Automation systems tends to have a temporal aspect to them as some action or the entire flow may need to be executed at specific times, at a certain intervals. Scrapers, vulnerability scanners and social media bots are examples of things that you may want to run at schedule. Those using web scraping for lead generation or price intelligence need to relaunch the web scraper often enough to get up-to-date snapshots of data. Bug bounty hunters are interesting in performing continuous recon that entails periodically running bunch of tools that scan targets for changes to quickly find new vulnerabilities. Social media bot operators also need to run their campaigns at schedule.
So we use cron(1), right? Yes, if our automations are simple enough and have a single starting point. If you just need to launch a single shell script every night then setting up an entry on crontab in your server is perfectly fine. However, that is not always the case.
When your automation flow grow large enough and start having multiple entry points (e.g. you may want to run the entire flow at schedule, but some of it in response to a webhook) it will start to have a graph-theorethic aspect to it. You will have multiple interrelated tasks (vertices) that have temporal/informational dependencies (directed edges) between them. For example, to run data enrichment step you first need to have a scraped dataset, thus there would be a directed edge between node representing scraping step to a node representing enrichment step. There will be a potential for error conditions in some of the actions, but not all errors will be serious enough to make everything fail. When things get complex enough, it becomes harder and harder to run bunch of tools from a shell script or crontab entry, especially if you need some flexibility to adjust the flow on as-needed basis. This kind of setup becomes fragile, unmanageable mess over time.
Thus we need something beyond cron. We need cron-on-steroids that will automatically run our actions in the correct order and provides a mechanism for error handling. I found that n8n automation platform fits these requirements when installed on Linux/Unix environment (this could be a small, cheap VPS or Vagrant-managed virtual machine). For instructions on how to prepare the environment, see:
In this environment, we also need to install some Python modules for the sample workflow we are going to build soon:
$ sudo apt-get install python3-pip
$ sudo pip3 install -U scrapy pandas openpyxl
We are going to build a simple n8n workflow to run a Scrapy project, a small script for converting CSV file to Excel-compatible spreadsheet and some extra steps to send/upload the final file that is going to be an output of the workflow.
So let’s clone a git repo containing a Scrapy project we want to run:
$ cd /vagrant
$ git clone https://github.com/rl1987/trickster.dev-code.git
The command to run Scrapy project of interest would be:
$ cd /vagrant/trickster.dev-code/2022-02-13-introduction-to-scrapy-framework/books_to_scrape/ && scrapy runspider books_to_scrape/spiders/books.py -o books.csv -s LOG_ENABLED=False
We use cd(1) to make this command invariant to the current working directory that it is being executed from. We also disable logging to standard error because n8n has only a fairly small buffer for storing an output. Emitting too much logs cause an error in n8n flow. If we needed logging, we could redirect logs to a file.
At /vagrant/csv_to_xlsx.py we put a very basic Python script that will
convert CSV file to Excel spreadsheet:
#!/usr/bin/python3
import sys
import pandas as pd
def main():
df = pd.read_csv(sys.argv[1])
df.to_excel(sys.argv[1].replace(".csv", ".xlsx"), index=None, header=True)
if __name__ == "__main__":
main()
This script expects a single argument that is supposed to be a full path to CSV file. We would run it like this:
$ python3 /vagrant/csv_to_xlsx.py /vagrant/trickster.dev-code/2022-02-13-introduction-to-scrapy-framework/books_to_scrape/books.csv
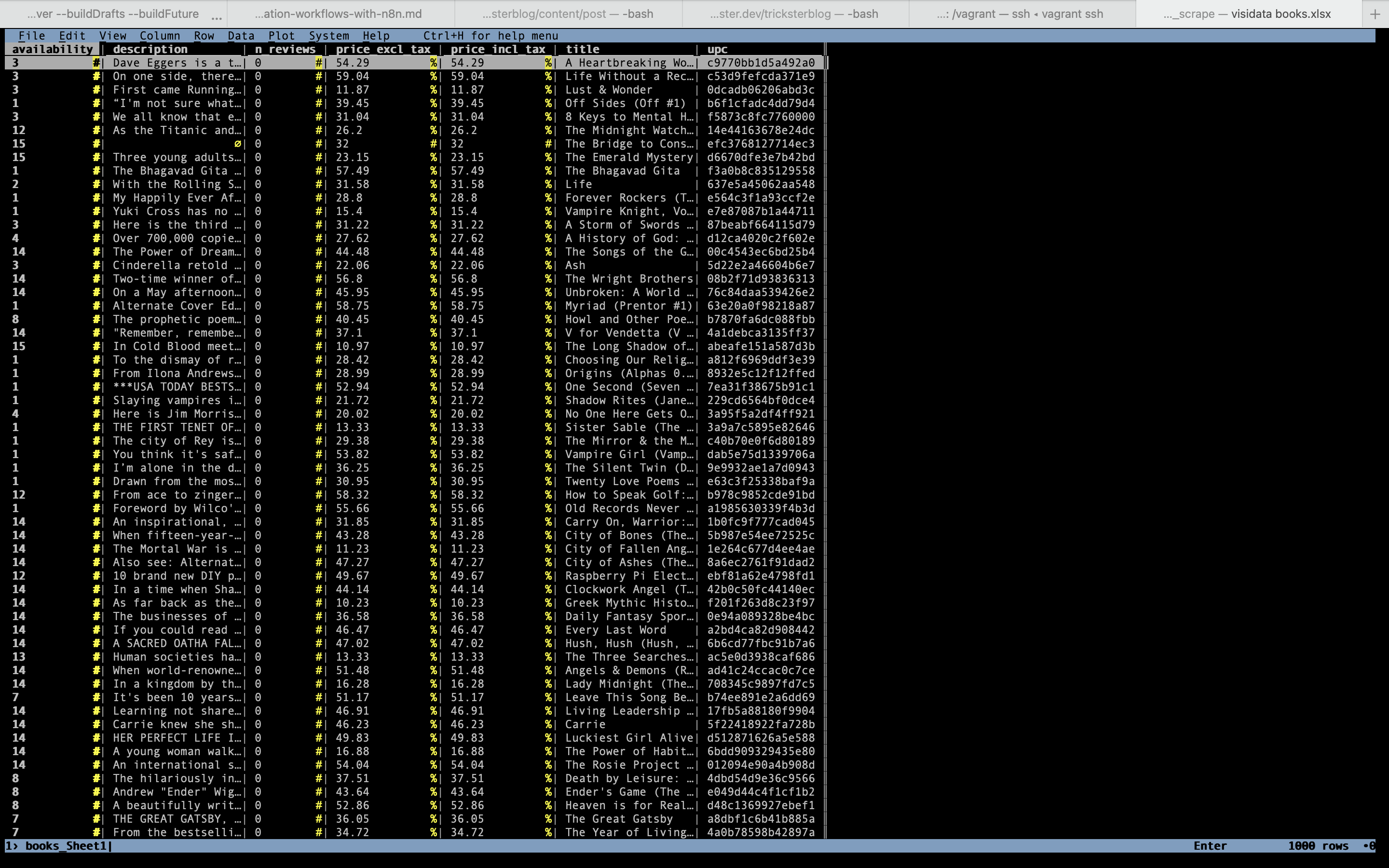
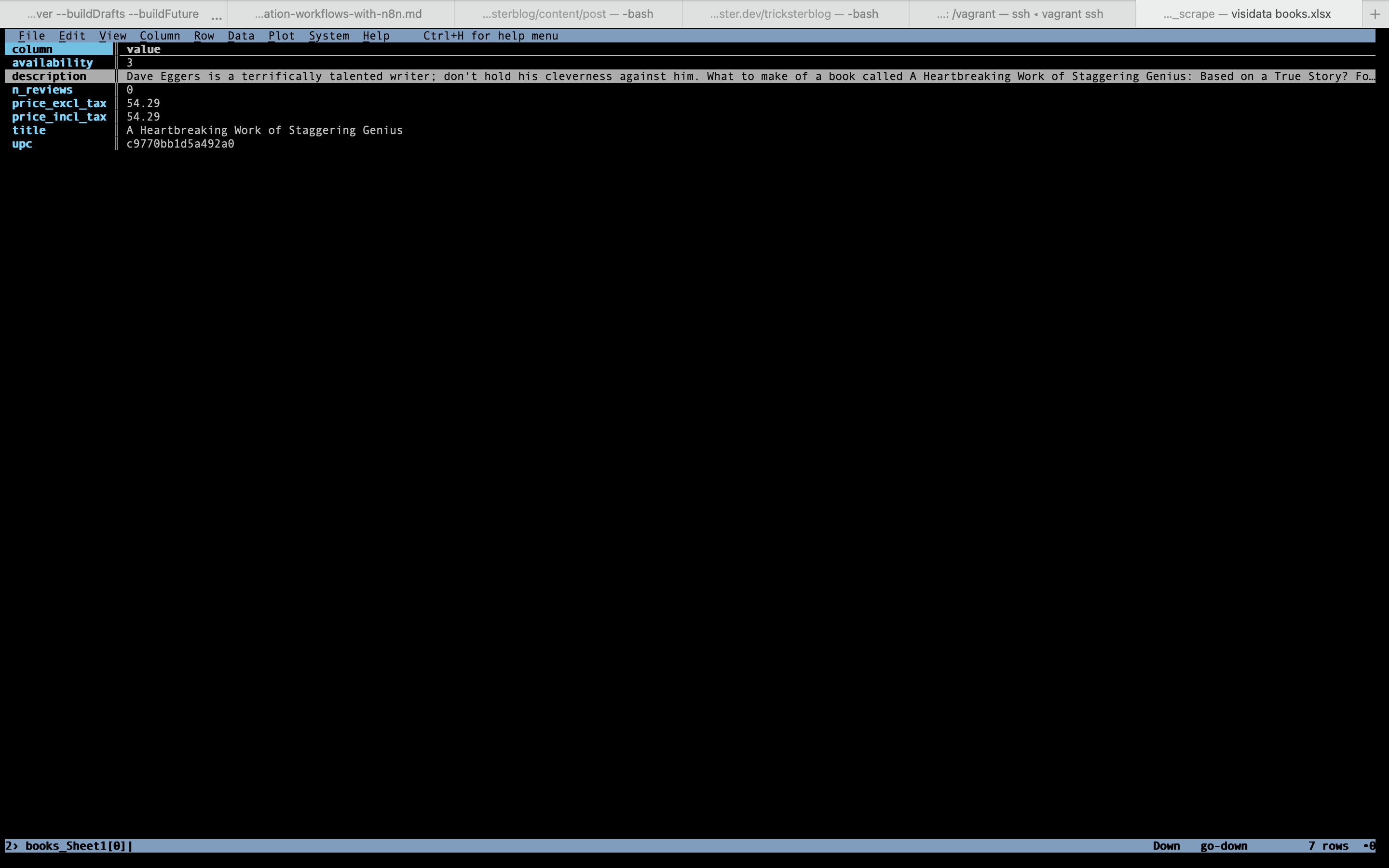
Opening the resulting file in Visidata allows us to quickly verify the correctness of the transformation.
{kind=link}
{kind=link}
Access the n8n web interface via web browser through port 5678. Once you go through the onboarding steps (you can skip account creation if you are going to be only one using your n8n instance) you will be presented with a blank workflow page with only the Start node present (it cannot be removed, but can be disconnected or disabled when no longer needed).
{kind=link}
{kind=link}
Press the “Add Node” (plus sign) button on the top-right corner. You will be presented with searchable list of nodes (actions) that you can use to build your flow.
{kind=link}
We need “Execute Command” node that we choose from the list. Upon choosing this node we will be presented with modal screen to set it up. We put the command to run the Scrapy spider into the text field for the command.
{kind=link}
Click outside the modal view to dismiss it. Now we have new, currently disconnected node on the screen.
{kind=link}
At this point we don’t worry about cronjobs and the like, so let’s connnect it to Start node by dragging the line between them.
{kind=link}
{kind=link}
This is already a very simple n8n flow that we can launch by pressing “Execute Workflow” button on the bottom.
Let us add new node for file conversion step. If you do this with the first node highlighted n8n will automatically connect it for you. To avoid confusion, we can rename the nodes to something more descriptive than their initial names.
{kind=link}
Furthermore, we can click the little setting button and write down some notes about the node that can optionally be shown in the flow.
{kind=link}
Another thing we can enable in the node settings is retries on error. This is not needed for the conversion step, but scraping step may fail due to the site being down or some other reasons beyond our control. Thus you may want to enable retrying with number of retries and delay between retries being some values that are sensible for your use case. Some actions in your flow may not be critical and of little importance. You may want to switch on the “Continue On Fail” switch for these actions. That way, an error in some unimportant step does not bring down the entire workflow.
{kind=link}
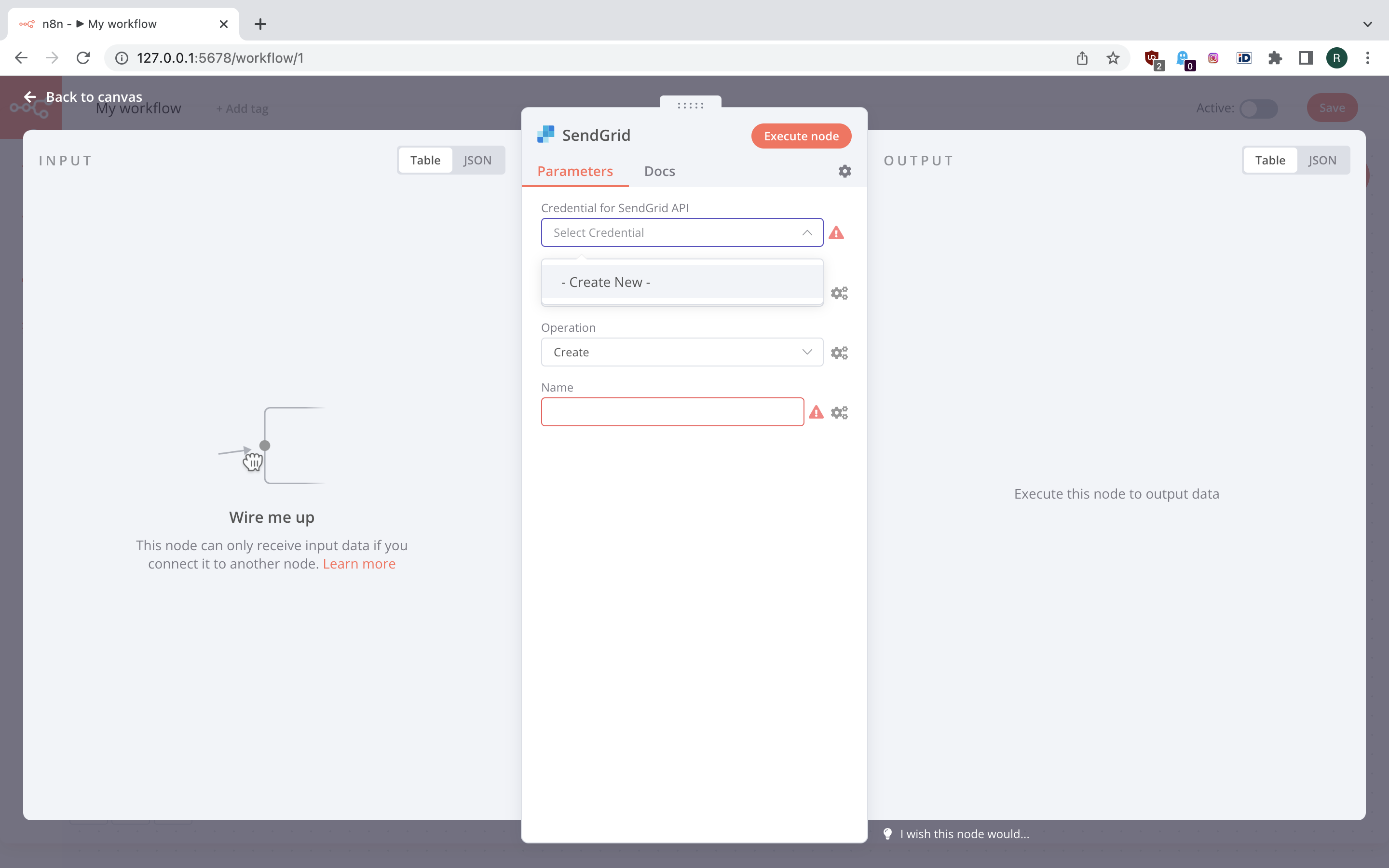
Now let us send an email. We can use either generic Mail node or one of the nodes for integrating into email provider (Gmail, Mailchimp, etc.). To demonstrate an integration into external system, we pick SendGrid node.
{kind=link}
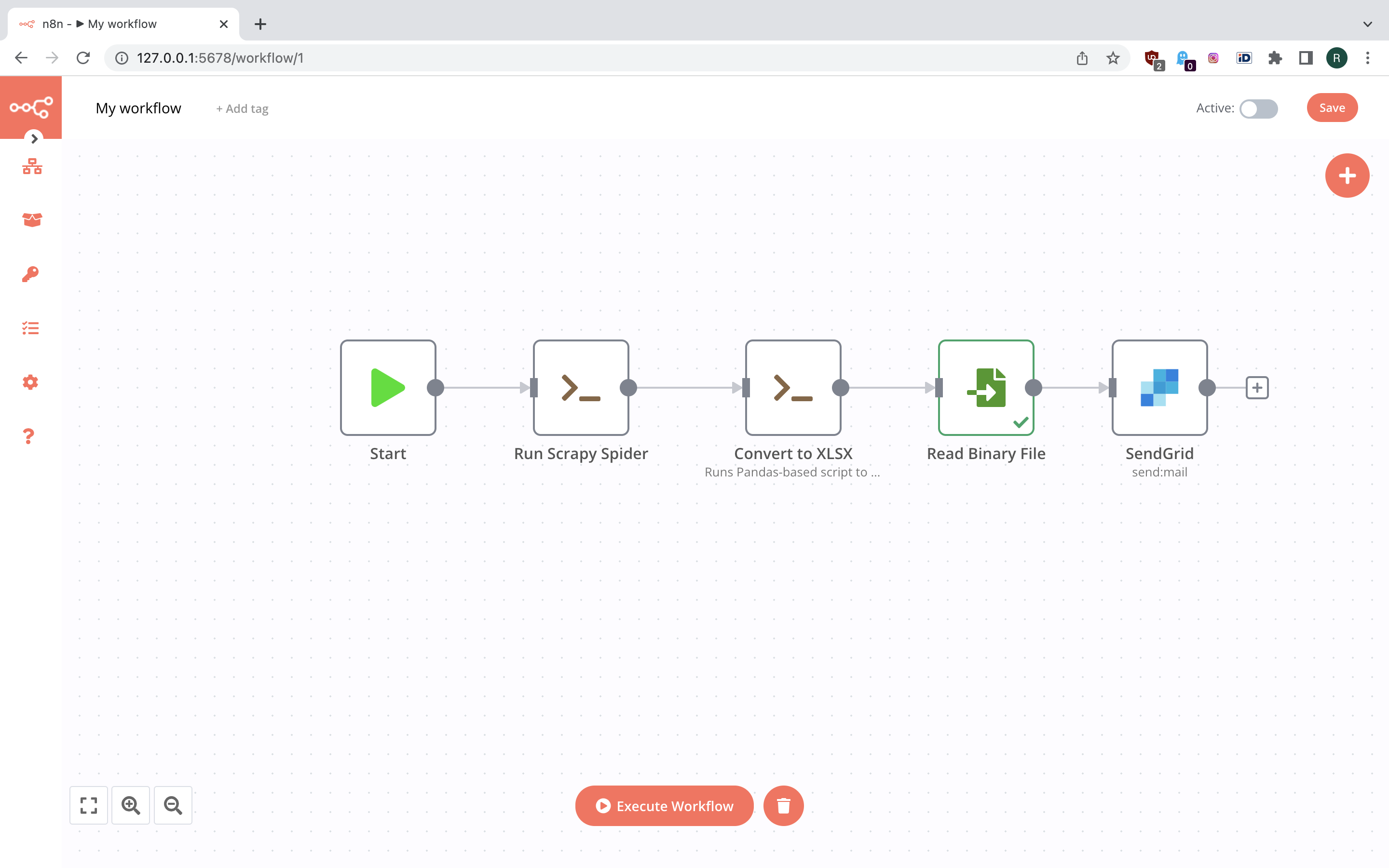
Now we need to add credentials. Click credential selection drop-down and choose “Create New”. This will present you a new modal view to put your SendGrid API key into. Once we save the API key, we can choose the SendGrid account in the drop down. Now we can fill the form with details about email we want to be sending. Note that credentials are stored separately from the workflows and can be edited by accessing menu option on the side. But one thing is missing - we need the binary data for the attachment. Thus we put this node aside for a moment and add a “Read Binary File” node. We set it up to read XLSX file from the conversion step, then wire it up between conversion and email sending nodes.
{kind=link}
{kind=link}
Now we come back to SendGrid node, scroll to the bottom of the form, click “Add fields”
and pick “Attachments” from the list. New textfield will appear. We need to set up data transfer
here. Put the property name from previous node in here. By default, this will be data.
Execute the node to test it - this will execute all the previous nodes in the flow.
{kind=link}
{kind=link}
We also want to upload our spreadsheet file to S3-compatible Digital Ocean Spaces bucket. To set it up on Digital Ocean side, create Spaces bucket and follow the procedure to get API credentials for accessing it. n8n provides two kinds of nodes for S3 API - AWS-specific one and generic variant. We choose the latter.
{kind=link}
Like we did with SendGrid, we fill in API access credentials (endpoint and region
fields must match the DO region your bucket is created in). Then we make sure
that Resource is selected to be File and Operation is Upload. We put out bucket
and file names into their respective text fields. We set Binary Property to data
as that is what is being set in previous node that reads XLSX file.
{kind=link}
{kind=link}
Now we can verify that file indeed gets uploaded by executing the node and checking the bucket.
{kind=link}
We got the flow working, but we need it triggered based on time. Thus we add the Cron node. For the sake of the example, we set trigger time to every midnight (we could have more elaborate schedule if we wanted).
{kind=link}
We disconnect the Start node and put the Cron node in its place.
{kind=link}
{kind=link}
To tidy things up and to provide visual aid for finding where does the workflow end, we connect the “No operation, do nothing” node to outputs of SendGrid and S3 nodes. This is technically not necessary and does not change the functionality in any way, but will make bigger flows more readable.
{kind=link}
But what if this entire thing fails due to some critical error? We would like to know about this. We can set up another workflow that would be executed to notify us about error condition. This can be done by entering workflow settings through side pane by choosing “Settings” under “Workflows”. We can create a new workflow for error handling (there’s some template ones from n8n communnity) and set it here.
{kind=link}
If we wanted the workflow to start based on some user action we could use other trigger nodes than Cron. There are nodes for web hook, email being received and so on.
We have shown how an interrelated collection of actions can be made more tractable by using n8n system to rework into more visual form. Furthermore, error handling mechanisms are provided at action level and at workflow level. We also have pre-developed components for integrations. Thus n8n can be used as flexible way to build higher order automation workflows that consist of launching Python scripts or other tools and composing them into larger system.
I do not suggest people to buy into No Code hype however. n8n alone would not be a right tool for more fine-grained, lower level kind of engineering, such as reproducing complex API flows to automate against automation-hostile systems. Many talkers have been talking about how No Code solutions that you may not even need to host yourself (at the cost of vendor lock-in) make it easier to build internal tools or even SaaS apps. That is only true at sufficiently low levels of complexity and scale. Once things get hard enough, it becomes necessary to think in computational terms. Things like n8n do have their value, but overreliance on drag-and-dropping your business logic on some GUI will constrain you to an environment and way of working that is grossly suboptimal for dealing with complexity. There’s a reason why we did not reproduce the stuff that goes on in the Scrapy project by reimplementing it with n8n nodes despite n8n having some capability to scrape sites and our Scrapy project being very basic.
I cannot stress this enough: if you want to build software systems, learn to fucking code!