Some internet research activities are based not only on the present data, but also on historical data that was, but no longer is posted online. As of late 2023, Internet Archive has over 842 billion web page snapshots stored and available for retrieval. We will go through a simple example of how scraping pre-crawled pages from Wayback Machine can be used to gather historical data for data science purposes. To look into Iowa inmate population trends, we will be scraping historical snapshots of Iowa Department of Corrections inmate statistics page. Data of interest is in “Current Count” and “Institution” columns of the table. We will do data scraping and wrangling in Python with Pandas dataframe library.
To quickly view the available snapshots for this page we search it through Archive.org front page. But there seems to be a little complication. Only two snapshots are available, which would not be sufficient for our purposes.
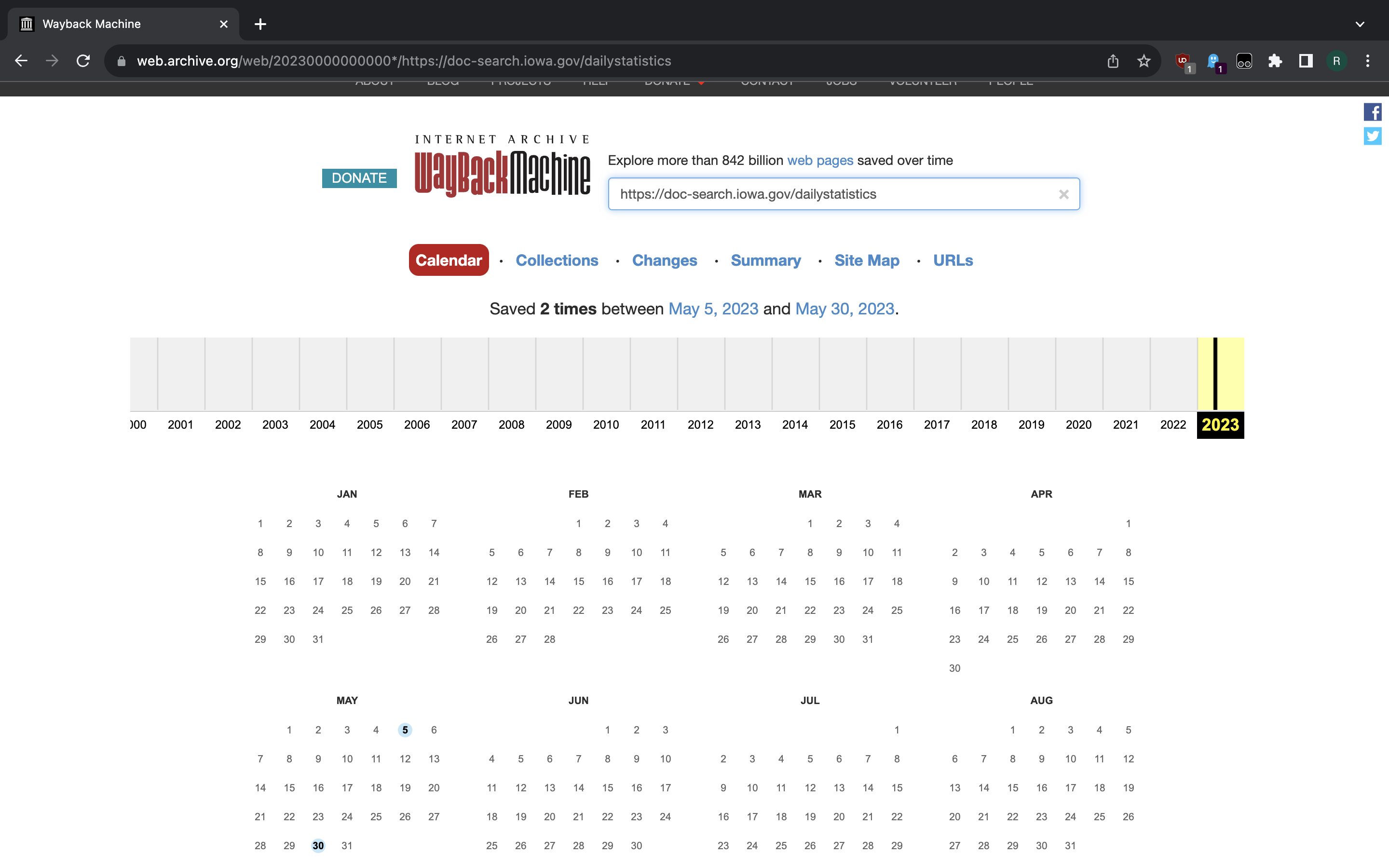{kind=link}
Thus we must backtrack a little. Searching for the domain - doc-search.iowa.gov -
on Wayback Machine gives us only 5 snapshots. It seems this domain is pointing
to fairly new (sub)site that is primarily meant for looking up prisoners in
Iowa and only secondarily to provide overall inmate statistics. The primary
domain for Iowa Dept. of Corrections is doc.iowa.gov. Exploring snapshots
for this site reveals that until some time in 2023 it had a statistics page
at following URL:
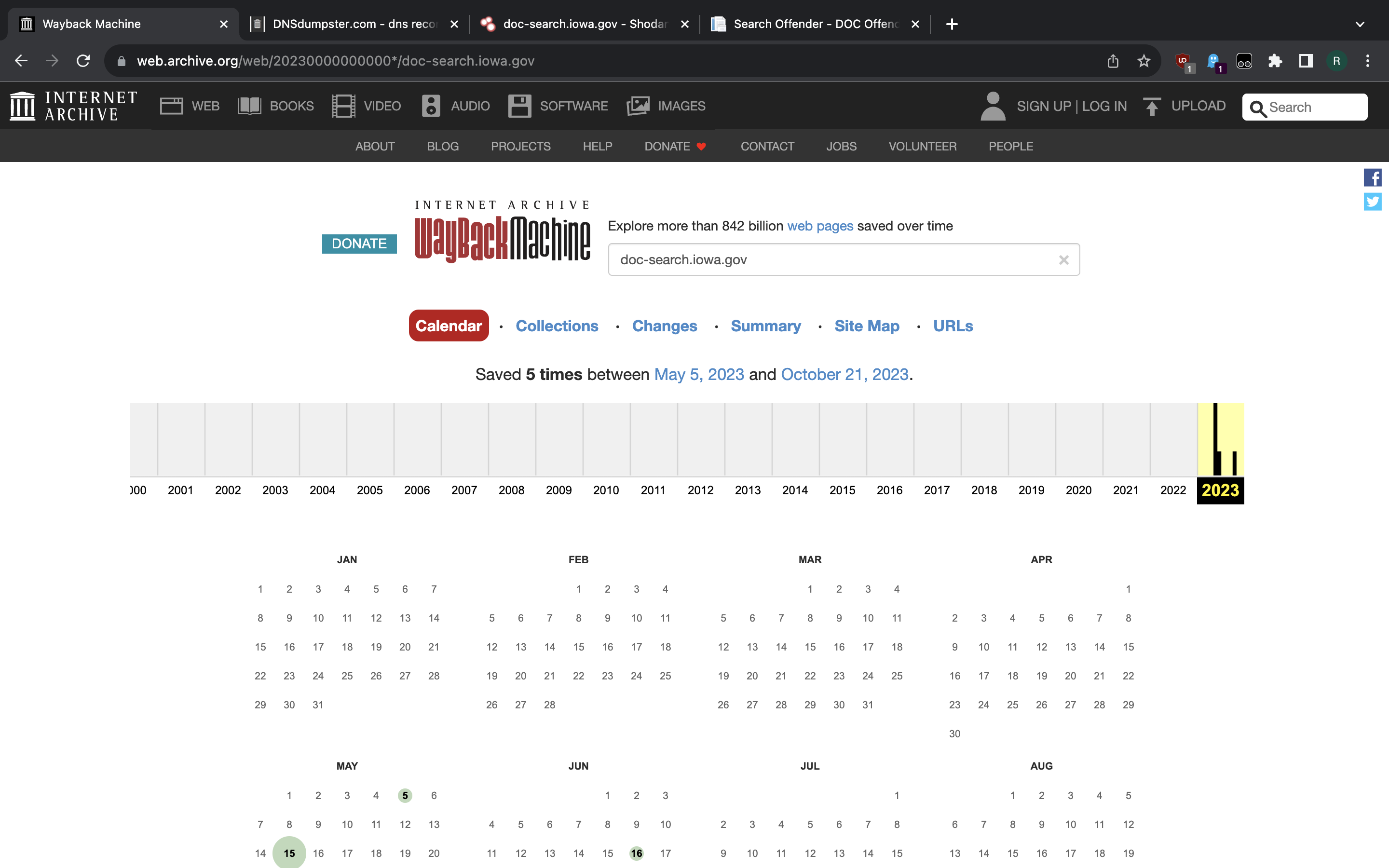{kind=link}
{kind=link}
We are after data on all available snapshots of this page.
To check for snapshot availability we can call the
/wayback/available
API endpoint with the URL of interest:
$ curl "https://archive.org/wayback/available?url=https://doc.iowa.gov/daily-statistics" | jq
{
"url": "https://doc.iowa.gov/daily-statistics",
"archived_snapshots": {
"closest": {
"status": "200",
"available": true,
"url": "http://web.archive.org/web/20230429064712/https://doc.iowa.gov/daily-statistics",
"timestamp": "20230429064712"
}
}
}
How do we get the list of snapshots? Internet Archive CDX API is a flexible way to search for snapshots by URL and secondary criteria: HTTP status code, timeframe and MIME type of the content. By default this API provides output in CDX table format that looks as follows:
$ curl "http://web.archive.org/cdx/search/cdx?url=doc.iowa.gov&limit=5"
gov,iowa,doc)/ 20170323172420 https://doc.iowa.gov/ text/html 200 L4NPH6MSVTZBRCD6CUTTQ2Y66OKY5Y3S 6904
gov,iowa,doc)/ 20170323172435 https://doc.iowa.gov/ text/html 200 BPFQVM2VIW32BNVM7LJ23QTXN7TDTPIL 6906
gov,iowa,doc)/ 20170323172720 https://doc.iowa.gov/ text/html 200 76LUVXUPNL3NPGU246YM3YQ6VNOOVIVH 6907
gov,iowa,doc)/ 20170416221430 https://doc.iowa.gov/ text/html 200 6VMMWJRPN33DAGREX54WSLFG367NCCEF 7113
gov,iowa,doc)/ 20170417071150 https://doc.iowa.gov/ text/html 200 OZMIM56F6OM5IL3HXTWBJZQCMGVRBYTB 7119
We can get a JSONified version of this table by passing output=json URL parameter:
$ curl "http://web.archive.org/cdx/search/cdx?url=doc.iowa.gov&limit=5&output=json"
[["urlkey","timestamp","original","mimetype","statuscode","digest","length"],
["gov,iowa,doc)/", "20170323172420", "https://doc.iowa.gov/", "text/html", "200", "L4NPH6MSVTZBRCD6CUTTQ2Y66OKY5Y3S", "6904"],
["gov,iowa,doc)/", "20170323172435", "https://doc.iowa.gov/", "text/html", "200", "BPFQVM2VIW32BNVM7LJ23QTXN7TDTPIL", "6906"],
["gov,iowa,doc)/", "20170323172720", "https://doc.iowa.gov/", "text/html", "200", "76LUVXUPNL3NPGU246YM3YQ6VNOOVIVH", "6907"],
["gov,iowa,doc)/", "20170416221430", "https://doc.iowa.gov/", "text/html", "200", "6VMMWJRPN33DAGREX54WSLFG367NCCEF", "7113"],
["gov,iowa,doc)/", "20170417071150", "https://doc.iowa.gov/", "text/html", "200", "OZMIM56F6OM5IL3HXTWBJZQCMGVRBYTB", "7119"]]
This is still not quite the shape of data that most modern JSON APIs provide,
but we can work with that by using read_json() function
from Pandas:
$ python3
Python 3.11.6 (main, Oct 2 2023, 20:46:14) [Clang 14.0.3 (clang-1403.0.22.14.1)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas as pd
>>> df = pd.read_json("http://web.archive.org/cdx/search/cdx?url=doc.iowa.gov&limit=5&output=json")
>>> df
0 1 2 3 4 5 6
0 urlkey timestamp original mimetype statuscode digest length
1 gov,iowa,doc)/ 20170323172420 https://doc.iowa.gov/ text/html 200 L4NPH6MSVTZBRCD6CUTTQ2Y66OKY5Y3S 6904
2 gov,iowa,doc)/ 20170323172435 https://doc.iowa.gov/ text/html 200 BPFQVM2VIW32BNVM7LJ23QTXN7TDTPIL 6906
3 gov,iowa,doc)/ 20170323172720 https://doc.iowa.gov/ text/html 200 76LUVXUPNL3NPGU246YM3YQ6VNOOVIVH 6907
4 gov,iowa,doc)/ 20170416221430 https://doc.iowa.gov/ text/html 200 6VMMWJRPN33DAGREX54WSLFG367NCCEF 7113
5 gov,iowa,doc)/ 20170417071150 https://doc.iowa.gov/ text/html 200 OZMIM56F6OM5IL3HXTWBJZQCMGVRBYTB 7119
It misread column labels in the first line, but we can trivially fix it:
>>> headers = df.iloc[0]
>>> df = pd.DataFrame(df.values[1:], columns=headers)
>>> df
0 urlkey timestamp original mimetype statuscode digest length
0 gov,iowa,doc)/ 20170323172420 https://doc.iowa.gov/ text/html 200 L4NPH6MSVTZBRCD6CUTTQ2Y66OKY5Y3S 6904
1 gov,iowa,doc)/ 20170323172435 https://doc.iowa.gov/ text/html 200 BPFQVM2VIW32BNVM7LJ23QTXN7TDTPIL 6906
2 gov,iowa,doc)/ 20170323172720 https://doc.iowa.gov/ text/html 200 76LUVXUPNL3NPGU246YM3YQ6VNOOVIVH 6907
3 gov,iowa,doc)/ 20170416221430 https://doc.iowa.gov/ text/html 200 6VMMWJRPN33DAGREX54WSLFG367NCCEF 7113
4 gov,iowa,doc)/ 20170417071150 https://doc.iowa.gov/ text/html 200 OZMIM56F6OM5IL3HXTWBJZQCMGVRBYTB 7119
From the timestamp column we can derive the snapshot URL by treating the timestamp
as path component between https://web.archive.org/web/ and the original URL:
>>> df['snapshot_url'] = df['timestamp'].apply(lambda ts: 'https://web.archive.org/web/' + ts + '/https://doc.iowa.gov/')
>>> df['snapshot_url'].to_list()
['https://web.archive.org/web/20170323172420/https://doc.iowa.gov/', 'https://web.archive.org/web/20170323172435/https://doc.iowa.gov/', 'https://web.archive.org/web/20170323172720/https://doc.iowa.gov/', 'https://web.archive.org/web/20170416221430/https://doc.iowa.gov/', 'https://web.archive.org/web/20170417071150/https://doc.iowa.gov/']
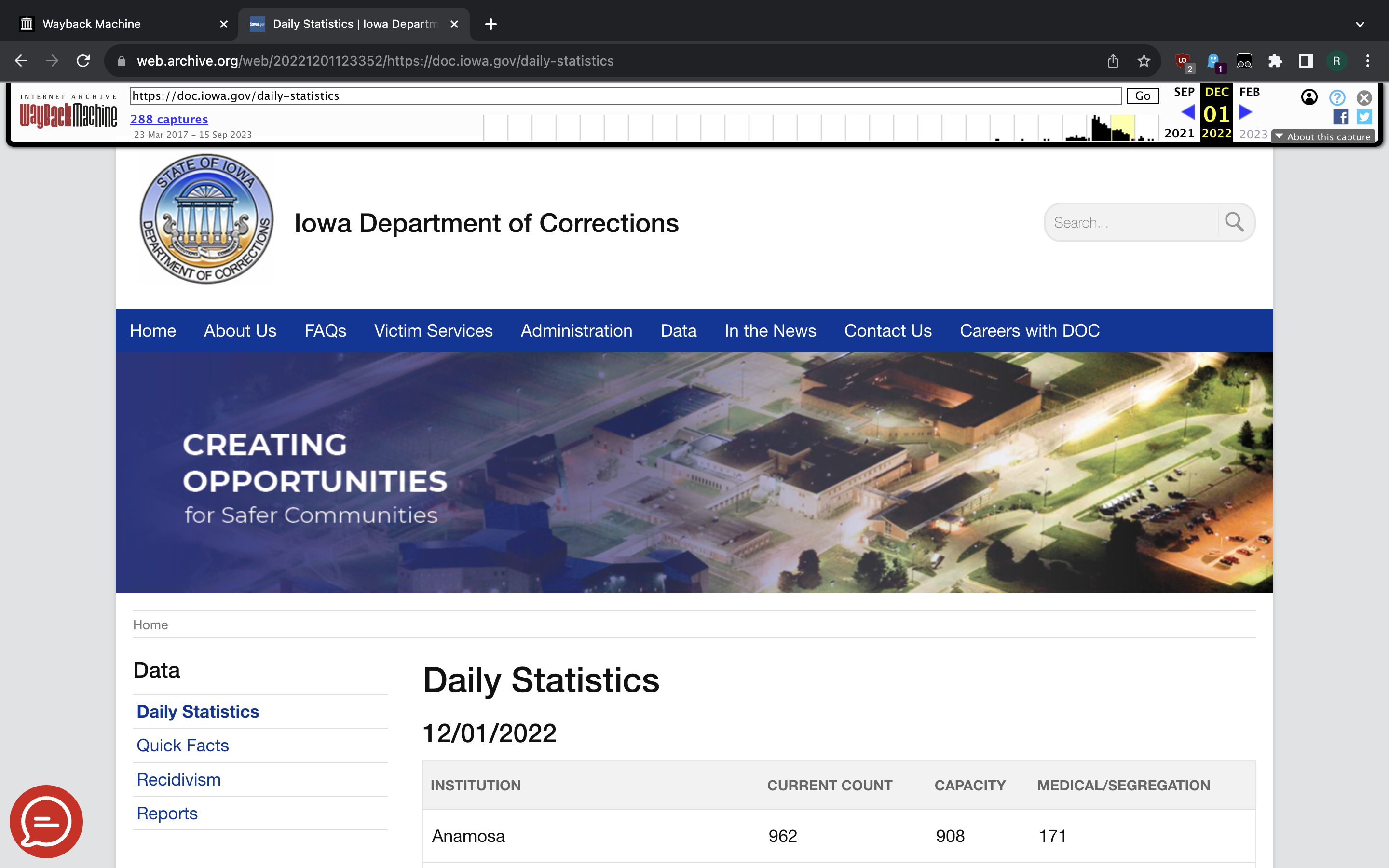
Each snapshot is the original HTML page with some extra stuff injected to help
us navigate the history of the page. Thus we can scrape it by using all the
usual web scraping techniques. Furthermore, the old pages we want to scrape
present the data in the basic HTML <table> element, which makes it easy
to scrape by using Pandas read_html() function:
>>> dfs = pd.read_html("https://web.archive.org/web/20210303210751/https://doc.iowa.gov/daily-statistics")
>>> stats_df = dfs[1]
>>> stats_df
Institution Current Count Capacity Medical/Segregation
0 Anamosa 943 911.0 171.0
1 Clarinda 962 750.0 46.0
2 Fort Dodge 1151 1162.0 75.0
3 Mitchellville 486 654.0 114.0
4 Minimum Live-Out 99 120.0 0.0
5 Oakdale 818 585.0 142.0
6 Forensic Psychiatric Hospital 9 0.0 28.0
7 Fort Madison 708 612.0 153.0
8 Mount Pleasant 815 776.0 80.0
9 Newton-Medium 853 762.0 197.0
10 Minimum 175 252.0 6.0
11 Rockwell City 432 245.0 18.0
12 MPCF Minimum Live-Out 86 104.0 0.0
13 INSTITUTIONAL TOTALS 7537 6933.0 1030.0
14 % overcrowded by 8.71% NaN NaN
To clean up the data, let us drop the last two columns and last two rows:
>>> stats_df = stats_df[['Institution', 'Current Count']]
>>> stats_df = stats_df[:-2]
>>> stats_df
Institution Current Count
0 Anamosa 943
1 Clarinda 962
2 Fort Dodge 1151
3 Mitchellville 486
4 Minimum Live-Out 99
5 Oakdale 818
6 Forensic Psychiatric Hospital 9
7 Fort Madison 708
8 Mount Pleasant 815
9 Newton-Medium 853
10 Minimum 175
11 Rockwell City 432
12 MPCF Minimum Live-Out 86
Lastly, let us tweak names of some sub-entries:
>>> stats_df.loc[stats_df['Institution'] == "Forensic Psychiatric Hospital", 'Institution'] = "Oakdale - Forensic Psychiatric Hospital"
>>> stats_df.loc[stats_df['Institution'] == "Minimum", 'Institution'] = "Newton-Minimum"
>>> stats_df.loc[stats_df['Institution'] == "Minimum Live-Out", 'Institution'] = "Mitchellville - Minimum Live-Out"
>>> stats_df
Institution Current Count
0 Anamosa 943
1 Clarinda 962
2 Fort Dodge 1151
3 Mitchellville 486
4 Mitchellville - Minimum Live-Out 99
5 Oakdale 818
6 Oakdale - Forensic Psychiatric Hospital 9
7 Fort Madison 708
8 Mount Pleasant 815
9 Newton-Medium 853
10 Newton-Minimum 175
11 Rockwell City 432
12 MPCF Minimum Live-Out 86
By now we have prototyped finding and parsing page snapshots in Python REPL environment. Let us put everything together into a Python script:
#!/usr/bin/python3
from urllib.parse import urlencode
import time
import sys
import pandas as pd
ORIG_URL = "https://doc.iowa.gov/daily-statistics"
def get_snapshot_urls():
params = {"url": ORIG_URL, "output": "json", "filter": "statuscode:200"}
cdx_url = "http://web.archive.org/cdx/search/cdx" + "?" + urlencode(params)
print(cdx_url)
df = pd.read_json(cdx_url)
headers = df.iloc[0]
df = pd.DataFrame(df.values[1:], columns=headers)
df["snapshot_url"] = df["timestamp"].apply(
lambda ts: "https://web.archive.org/web/" + ts + "/https://doc.iowa.gov/"
)
return df["snapshot_url"].to_list()
def scrape_stats_table(url):
dfs = pd.read_html(url)
print(url)
stats_df = dfs[1]
stats_df = stats_df[["Institution", "Current Count"]]
stats_df = stats_df[:-2]
stats_df.loc[
stats_df["Institution"] == "Forensic Psychiatric Hospital", "Institution"
] = "Oakdale - Forensic Psychiatric Hospital"
stats_df.loc[stats_df["Institution"] == "Minimum", "Institution"] = "Newton-Minimum"
stats_df.loc[
stats_df["Institution"] == "Minimum Live-Out", "Institution"
] = "Mitchellville - Minimum Live-Out"
stats_df["url"] = url
print(stats_df)
return stats_df
def main():
snapshot_urls = get_snapshot_urls()
print("Found {} snapshots".format(len(snapshot_urls)))
result_dfs = []
for url in snapshot_urls:
try:
stats_df = scrape_stats_table(url)
except KeyboardInterrupt:
sys.exit(1)
except:
time.sleep(5)
try:
stats_df = scrape_stats_table(url)
except KeyboardInterrupt:
sys.exit(1)
except:
continue
result_dfs.append(stats_df)
result_df = pd.concat(result_dfs)
result_df.to_csv("iowa_doc.csv", index=False)
if __name__ == "__main__":
main()
We don’t store the timestamp directly in the scraped data as we can trivially recover it from the URL:
from datetime import datetime
import pandas as pd
def convert_timestamp(timestamp):
return datetime(year=int(timestamp[0:4]),
month=int(timestamp[4:6]),
day=int(timestamp[6:8]),
hour=int(timestamp[8:10]),
minute=int(timestamp[10:12]),
second=int(timestamp[12:14]))
df = pd.read_csv('iowa_doc.csv')
df['timestamp'] = df['url'].apply(lambda url: url.split('/')[4])
df['timestamp'] = df['timestamp'].apply(convert_timestamp)
Some open source projects relying on Internet Archive API:
- gau - a recon tool to fetch known URLs from several sources, including Internet Archive.
- Bellingcat’s wayback-google-analytics is OSINT tool to dig up Google Analytics identifiers for finding associations between websites.